Speaking from a recent graduate of high school
So I just graduated high school without ever taking a computer science or coding class. It was mainly through my own learning and exploration did I start to get into this field. And trust me, I love it. Reinforcement learning, at least my limited understanding of it right now, involves training a model or an agent to make decisions in an environement, both short-term and long-term, that maximizes the cumulutivate reward in said environment.
Minecraft
This year, for example, I’m working with Minecraft agents. The agent is the A.I. playing Minecraft, and the environment is the world the A.I. spawns in. Depending on what you make the goal for the agent to be, the goal is to train the agent to take steps to reach that goal. How does the agent learn? That’s where reward comes in. Every action the agent takes, ex. chop a wood block, break a dirt block, build a crafting table, the environment returns a reward and by using various reinforcement learning algorithms, we’re able to maximize that reward. But coming straight out of high school without even taking advanced math courses such as Calculus 3 or linear algebra, it’s hard to understand these deep learning techniques. For example, I’m currently using a reinforcement learning algorithm called Proximal Policy Optimization, or PPO for short.
Here’s the general mathematical theory behind it

Anyone who doesn’t have a decent understanding of math won’t be able to understand that. And for those who want to get started in machine learning, you got to have a strong foundation in math. That was a key takeway right from the get go when I started all of this.
PPO and OpenAI Spinning Up
From my limited understanding (notice how I keep saying limited? I just started all of this stuff recently BTW so I’m writing this blog to
- really see if I can understand it. If I can write about it here explaining it, then I think I’ve made some progress learning. And
- emphasize how you probably shouldn’t rely on me for your reinforcement learning tutorial.
This is more so me explaining it to myself. Sort of. I do, however, recommend the OpenAI Spinning Up tutorial which is absolutely fantastic for those wanting to get into reinforcement learning. It certainly has helped me a ton.
Anyway, back to PPO. PPO utilizes policy optimization. But what is a policy? Remember how we want to train the agent to take the action that maximizes reward? This is what the policy is. The policy returns the action that maximizes the reward. The policy we want an agent to learn basically becomes its brain. And in policy optimization types of RL algorithms like PPO, we directly optimize that policy to maximize reward for our goals. However, PPO is a bit different. In proximal policy optimization, at least the way I understand it, is instead of directly maximizing the policy function, we maximize a surrogate objective function, with this objective function giving a conservative estimate for how much the reward will change with each action. And I say conservative because PPO limits big changes to your policy function which could potentially be disastrous in your training. That’s the gist of it. It may not be explained well so I’m going to leave it to the actual people who come up with PPO. Here’s the link to their paper. Wow, that was a hefty second post! Not what I expected. If you read untill the end, you most likely are interested in my work or machine learning and if so great! Because I’d find all of this stuff quite dull and not understandable if I had no background in computer science.
(Update) Hello it’s older me speaking now!
Looking back at my high school self, I can understand why this was tough to understand. But now as I gained a bit more mathematically maturity and studying more of the RL theory, I’ve come to understand PPO much more now. What my old self said is pretty good, and I’m here writing about it a bit more.
I talked about these policy optimization types of algorithms and what I didn’t explain very clearly was that in these direct policy optimization methods, the policy outputs a probability distribution of all the actions which introduces a stochastic factor to the agent and allows for continuous actions. We ideally want some sort of stochastic factor to promote exploration rather than exploitation. See this post for a better idea why. We also may or may not want support for continuous actions becuse our environment maybe not all just be discrete actions. Think of driving a car and turning the steering wheel. The number of degrees you turn the steering wheel is continuous. Essentially, in these types of algorithms, we train the agent to make the more favorable actions have higher probabilites of being sampled and the negative ones have lower probabilites! Makes sense.
In most cases, these algorithms are policy gradient methods where we perform gradient ascent on our agent’s parameters to maximize our rewards. Mathematically, we want to maximize the expected value of our current and future rewards in a trajectory (a full run through of our agent before reaching a terminal state. That could be the game ending, the agent dying, etc.). We denote the trajectory with $\tau$.
\[\mathbb{E}[R(\tau)]\]where $R(\tau)$ is our reward from the whole trajectory.
Now in proximal policy optimization, I mentioned how the idea was that we don’t want to big of a policy update to our agent. Imagine a robot trying to navigate a mountainous terrain. Too large of a policy update could lead to the robot taking a step that’s too long and lead to it falling off a cliff.

But we also don’t want too small of an update as our agent will take forever to learn then. PPO with a clipped objective basically limits how big of an update to our policy occurs. Notice how in the PPO objective function, we take the min of $r_t(\theta) * A_t$ and clip($r_t(\theta), 1 - \epsilon, 1 + \epsilon) * A_t$.
Let’s unpack these variables. Before PPO, there is another RL algorithm called trust region policy optimization and aims to do the same thing: limit how big we update our policy. Essentially, what they did was look at the ratio between the probability of a certain action being taken under the current policy and the same action being taken under the previous policy. They then muliplied that ratio by something known as the advantage function, $A_t$, which simply analyzes if an action that I took left me better off than before (better expected future rewards). A positive advantage means it did and a negative advantage means it made my state worse. The whole thing then get’s wrapped in an expected value because we’re dealing with expected rewards and probability distributions. Mathematically, it looks like this:
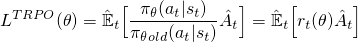
A bit of a notation thing. We usually denote the policy of our agent as $\pi$. We write $\pi_{\theta}$ to denote the policy with our given parameters $\theta$. These parameters are what we update in gradient ascent and so. Then, $\pi_{\theta}(a_t \vert s_t)$ is the probability that I take a certain action at time step $t$ given the state at time step $t$, $s$. In short, I see some state $s$. What’s the probability then I take some action $a$ after seeing this state? That’s what that’s basically saying.
A fallback of TRPO was that it gets a bit more complicated after that. You can read more about the differences here. PPO bsically takes the same objective from TRPO ($r_t(\theta)$), but adds a clipped version to it, saying you can only change that ratio between $(1 - \epsilon, 1 + \epsilon)$. This allows the policy to not get updated too much or too few and the authors of PPO found a value of $\epsilon = 0.2$ to be a good value.
Jeez! That was a lot to unpack and honestly I’m kind of impressed with my old high school self being able to tackle this type of stuff so young. Again, maturing a bit, I’ve gained a deeper understanding of all of this and it’s good to look back and reflect. But yeah that was a bit of PPO! This conservative approach has proved to be quite successful and being used everywhere! I used it in my summer project and it proved to be quite successful.